有道翻译2025的技术核心,在于其自研的“子曰”(Ziyue)千亿参数大模型。这一变革性技术通过深度理解上下文、精准捕捉语气和文化内涵,并融合多模态处理能力,从根本上超越了传统神经机器翻译(NMT)的局限。它不仅实现了从“句子级”到“篇章级”的翻译飞跃,更让翻译结果变得前所未有地精准、地道和富有“人情味”,标志着AI翻译已进入一个由超大规模模型驱动的全新智能时代。
作为深耕语言科技领域多年的公司,有道(www.youdao.com)见证并引领了翻译技术的数次迭代。从最初的统计机器翻译(SMT),到后来风靡一时的神经机器翻译(NMT),每一次技术浪潮都极大地提升了翻译的效率与质量。然而,用户对翻译的需求永无止境——我们不仅要求“翻得对”,更渴望“翻得好”、“翻得巧”。正是在这样的背景下,以“子曰”为代表的千亿级参数大语言模型(LLM)应运而生,为有道翻译的未来发展(Youdao Translate 2025)注入了颠覆性的力量。
文章目录
- 从NMT到LLM:翻译技术迎来范式转移
- 什么是“子曰”大模型?有道翻译的“新引擎”
- 千亿大模型如何颠覆传统翻译体验?
- 技术对比:有道“子曰”大模型 vs. 传统NMT
- 挑战与展望:有道翻译2025的未来之路
- 结语:千亿大模型,开启智能翻译新纪元
从NMT到LLM:翻译技术迎来范式转移
在探讨有道翻译的未来之前,我们必须理解其技术演进的脉络。过去数年,神经机器翻译(NMT)一直是行业的主流。它通过编码器-解码器(Encoder-Decoder)架构,将源语言句子映射到一个向量空间,再由解码器生成目标语言句子。NMT极大提升了翻译的流畅度,但其核心瓶颈在于“视野”有限。它通常以单个句子为处理单位,难以理解跨越多个句子的复杂指代关系、段落的整体逻辑以及文章的深层意图,导致在处理长文本时常常出现上下文割裂、前后矛盾的问题。
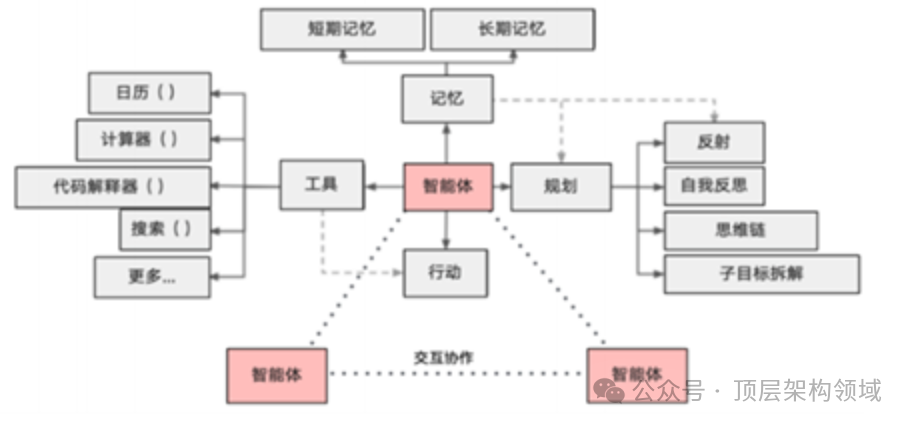
而大语言模型(LLM)的出现,则彻底改变了游戏规则。以有道“子曰”大模型为代表的LLM,拥有数千亿级别的参数,其“知识库”和“推理能力”呈指数级增长。它不再仅仅是一个“翻译工具”,更像一个精通多语言的“世界知识专家”。通过在海量数据上进行预训练,LLM学会了语言的底层规律、世界的常识知识和复杂的推理链条,从而实现了从“翻译”到“理解与再创作”的范式转移。
什么是“子曰”大模型?有道翻译的“新引擎”
“子曰”大模型是有道自主研发的、专为教育和语言应用场景深度优化的超大规模语言模型。它不仅是支撑有道全线产品的技术底座,更是驱动有道翻译2025向前迈进的核心引擎。那么,这个“新引擎”的特别之处究竟在哪里?
千亿参数的“力量”:它意味着什么?
“千亿参数”并不仅仅是一个数字游戏。更多的参数意味着模型拥有更强大的表征能力和记忆容量。这允许“子曰”模型:
- 存储更海量的知识: 涵盖语言学、文化、历史、科技等几乎所有人类知识领域,使其在翻译专业术语和文化背景时游刃有余。
- 学习更复杂的语言模式: 能够捕捉到传统模型无法识别的细微语法结构、修辞手法和言外之意。
- 进行更深层次的推理: 在翻译时,它能像人一样思考,理解代词“it”或“他”在长文中的确切指代对象,保证译文的连贯性和准确性。
简单来说,参数量的巨大提升,让“子曰”模型的认知深度发生了质变,使其从一个“语言转换器”进化为一个具备初步“思考能力”的“认知智能体”。
从单一翻译到多任务融合:子曰模型的架构优势
传统NMT模型通常是为“翻译”这一单一任务进行训练的。而“子曰”大模型则不同,它在预训练阶段就学习了包括文本生成、摘要、问答、代码编写在内的多种任务。这种多任务融合的架构带来了巨大的协同效应。
当“子曰”模型执行翻译任务时,它实际上是在调用其全面的语言能力。例如,它会利用其“摘要能力”来把握段落主旨,利用其“文本生成能力”来组织更优美的译文句式,甚至利用其“常识问答能力”来判断一个词语在特定语境下的最佳译法。这种多维能力的融合,让翻译不再是孤立的转换,而是一个综合了理解、推理、判断和表达的复杂认知过程。
千亿大模型如何颠覆传统翻译体验?
理论的革新最终要落实到用户体验的提升上。搭载了“子曰”大模型的有道翻译,正在从以下几个方面,彻底颠覆我们对机器翻译的认知。
超越“信达雅”:上下文感知与语篇级翻译
中国古代翻译家严复提出的“信、达、雅”是翻译的至高标准。传统NMT在“信”(准确性)和“达”(流畅性)上做得不错,但在“雅”(优美性)和深层“信”上力不从心。这正是“子曰”大模型的突破口。
凭借其强大的上下文感知(Context-aware)能力,“子曰”模型能够完整阅读并理解整个段落乃至全篇文章,实现真正的语篇级(Discourse-level)翻译。例如,对于一段描述历史事件的文字,它能确保所有人物、地点和时间的翻译在全文中保持一致;对于一篇小说,它能理解并传递作者铺设的伏笔和情感基调。这使得译文不再是零散句子的生硬拼接,而是一个逻辑清晰、结构严谨的有机整体。
告别生硬机翻:更地道、更具情感的表达
“机翻味”是传统翻译最被人诟病的一点。它往往能翻译出字面意思,却丢失了原文的语气、风格和情感色彩。“子曰”大模型通过学习海量的文学作品、社交媒体文本和剧本对话,对语言的“人情味”有了深刻的理解。
它能识别出一段话是正式的书面语还是轻松的口语,是讽刺还是赞美,是喜悦还是悲伤。在翻译时,它会选择最符合目标语言文化习惯和语境的词汇与句式。例如,将一句英文中的“That’s… interesting.”,它可能不再直译为“那很有趣”,而是根据上下文判断,翻译成更符合中文语境的“有点意思”、“耐人寻味”甚至带有反讽意味的“可真行”。
不仅仅是文本:多模态翻译的无限可能
未来的交流是多维的。“子曰”大模型的另一大革命性优势在于其多模态(Multimodal)处理能力。这意味着有道翻译不再局限于处理纯文本。
- 图片翻译: 能够识别图片中的文字(OCR),并结合图片内容(例如,一张菜单、一张海报)进行更精准的翻译。
- 语音翻译: 实现更自然的同声传译,不仅翻译内容,更能保留说话者的语气和停顿。
- 视频翻译: 未来甚至可以理解视频画面内容,为字幕翻译提供更丰富的背景信息,解决画面与字幕不匹配的问题。
这种能力的整合,将让有道翻译成为一个无处不在的全场景语言助手。
攻克低资源语言:知识迁移的力量
世界上有数千种语言,但很多语言的平行语料库(成对的翻译数据)非常稀少,这使得传统NMT难以训练出高质量的低资源语言(Low-resource Language)翻译模型。而“子曰”大模型的“知识迁移”能力为此提供了解决方案。
由于LLM在预训练阶段已经学到了关于世界和语言结构的通用知识,它可以将从高资源语言(如英语、中文)中学到的语法、语义规律,“迁移”到低资源语言上。这大大降低了对平行语料的依赖,使得有道翻译能够为更多小语种提供远超以往质量的翻译服务,促进了全球文化的交流与普惠。
技术对比:有道“子曰”大模型 vs. 传统NMT
为了更直观地展示技术代差,我们通过一个表格来对比“子曰”大模型驱动的翻译与传统NMT的区别:
| 特性维度 | 传统神经机器翻译 (NMT) | 有道“子曰”大模型驱动的翻译 |
|---|---|---|
| 上下文理解范围 | 句子级,对长距离依赖关系处理能力弱 | 篇章级,能理解段落、全篇逻辑 |
| 语境与风格处理 | 风格单一,倾向于生硬的字面翻译 | 高度情景化,能模仿不同风格、语气和情感 |
| 知识与常识 | 依赖训练数据中的显式知识,缺乏推理能力 | 内嵌海量世界知识,具备常识推理能力 |
| 多模态能力 | 通常仅支持文本 | 原生支持图文、音视频等多模态输入 |
| 低资源语言支持 | 效果差,严重依赖平行语料 | 通过知识迁移显著提升翻译质量 |
| 核心任务 | 语言转换 (Translation) | 理解与再创作 (Comprehension & Recreation) |
挑战与展望:有道翻译2025的未来之路
尽管千亿大模型带来了前所未有的机遇,但通往完美翻译的道路依然充满挑战。作为技术的引领者,有道对此有着清醒的认识。
我们面临的挑战:算力、成本与“AI幻觉”
首先是算力与成本。训练和运行千亿级模型需要巨大的计算资源,如何优化模型结构、降低推理成本,是让顶尖技术能够普惠大众的关键。其次是“AI幻觉”(Hallucination)问题,即模型可能会“一本正经地胡说八道”,捏造事实。有道正在通过事实校验、知识图谱融合等技术手段,持续提升翻译的可靠性。最后,数据的偏见与安全也是需要长期关注和解决的重要课题。
未来展望:个性化翻译与人机协同新范式
展望有道翻译2025及更远的未来,我们看到两个清晰的方向:
- 极致的个性化翻译: 未来的翻译服务将能学习每个用户的个人语言习惯和专业领域。为一名律师翻译合同,和为一名诗人翻译诗歌,模型会调用完全不同的知识和风格,提供“千人千面”的定制化服务。
- 无缝的人机协同: AI不会完全取代专业译员,而是成为他们最强大的助手。未来的翻译工作流将是AI完成初稿,并提供多种备选方案和背景知识,由人类专家进行最终的画龙点睛。这种人机协同的新范式,将把翻译的质量和效率推向新的高峰。
结语:千亿大模型,开启智能翻译新纪元
从解码人类语言的梦想出发,有道在翻译技术的道路上从未停止探索。今天,“子曰”千亿大模型的成功应用,不仅是有道自身技术实力的体现,更宣告了一个全新智能翻译纪元的到来。它让机器翻译不再是冰冷的代码转换,而是开始拥有智慧、情感和创造力。有道翻译2025,正致力于将这种划时代的技术力量,转化为每一个用户触手可及的、精准、智能、且充满温度的语言服务,真正打破语言的壁垒,连接世界的沟通。